Spreadsheet Semantics vs Database Semantics
Why Companies Choose Visual DB Over Airtable When Data Integrity Is Non-Negotiable
In Google Docs, multiple people can collaboratively edit a document. Two people can even simultaneously edit the same sentence. But just because you can doesn't mean you should. You're more likely than not to end up with a mangled sentence if two people edit the same sentence simultaneously.
The same is true for database records. Airtable lets multiple people edit the same record—whether knowingly or unknowingly—at the same time. This can go horribly wrong if there are logical relationships between fields in the record. Consider a medication table where a doctor wants to double a patient's total daily dosage from 500mg to 1000mg. One nurse doubles the pill strength from 250mg to 500mg (expecting the frequency to stay the same), while another nurse doubles the frequency from twice daily to four times daily (expecting the pill strength to stay the same). Each nurse is making a correct change in isolation, but when the changes are combined, the patient receives 2000mg/day—double what the doctor intended and potentially dangerous.
Airtable (and most tools with similar functionality, including NocoDB, Baserow and Retool) use what we call "spreadsheet semantics," where changes flow immediately and independently. It works beautifully for collaborative documents, but it can be disastrous for data with integrity requirements.
Understanding the difference between spreadsheet semantics and database semantics isn't just academic—it's the difference between a system that feels smooth and one that guarantees correctness.
What Are Spreadsheet Semantics?
Spreadsheet semantics follow a simple principle: changes propagate automatically and continuously to all users. While network latency means there's always some delay—typically a few seconds—the goal is for changes to appear as quickly as technically possible, without requiring an explicit save action.
Key Characteristics
Cell-level independence: Each cell operates as its own unit. There's no concept of "rows as atomic units." When you type in cell A1, it updates A1—period. The system doesn't care about the relationship between A1 and A2.
Instant visibility: Changes appear immediately for all users. There's no "save" or "commit" step. It's like multiple people typing in Google Sheets simultaneously—you see their cursor, watch values change in real-time.
Last-write-wins: When two people edit the same cell, whoever saves last overwrites the previous value. No error, no warning—the earlier change simply disappears.
No transaction boundaries: You can't say "update these three cells atomically or not at all." Each keystroke is its own independent operation with no rollback concept.
Spreadsheet semantics feel fast and fluid because there's no waiting, locking, or conflict resolution—but that speed comes at the cost of reliability.
The Problem with Spreadsheet Semantics
To understand why database semantics are necessary for critical data, we need to examine two specific problems that plague spreadsheet semantics: lost updates and write skew. (Note: for a detailed treatment of this topic see these lecture notes on concurrency control.)
Lost Updates
Lost update occurs when two concurrent transactions both read the same data, modify it, and write it back—a classic read-modify-write cycle. The problem arises when a committed value written by one transaction is overwritten by a subsequent committed write from a concurrent transaction.
For example, imagine a warehouse inventory system showing 100 units of a product in stock. Transaction A reads the quantity, subtracts 25 units for an order, and writes back 75. Transaction B reads the original 100 units (before seeing A's update), subtracts 40 units for a different order, and writes back 60. The final inventory shows 60 units—but Transaction A's 25-unit order has been completely lost, overwritten by Transaction B's update. Both transactions successfully completed their read-modify-write cycles, but one order's inventory deduction simply disappeared. The system now thinks it has 60 units when it actually has only 35 units remaining (100 - 25 - 40).
Write Skew
Write skew is a more subtle anomaly where two transactions read overlapping data, make decisions based on what they read, then write to different locations—creating an inconsistent state that neither transaction intended. Write skew happens when an update is made within a transaction based upon stale data—a value read by a transaction that has become stale due to a subsequent committed write from a concurrent transaction.
Unlike lost updates where transactions write to the same field and one overwrites the other, write skew involves transactions writing to disjoint sets of fields.
Consider our medication example: both users read the initial state showing 250mg pills taken twice daily (500mg/day total). User A decides to increase the dosage by doubling the pill strength to 500mg, while User B decides to increase it by doubling the frequency to four times daily. Each writes to a different field, both writes succeed, but the combination produces 2000mg/day—double what either user intended.
What Are Database Semantics?
Database semantics prevent both lost updates and write skew through explicit concurrency control. When multiple users attempt to modify the same data, the system detects conflicts and ensures only one change succeeds at a time. For our inventory example, when Transaction B attempts to save its update, the system recognizes that the data has changed since Transaction B originally read it. Transaction B receives an error message with the current inventory count (75 units, reflecting Transaction A's deduction), and must recalculate based on fresh data. Similarly, for the medication example, when the second nurse attempts to save their changes, the system detects that the record was modified and presents the current values—preventing the dangerous double-dose scenario. Users see explicit conflict notifications rather than silent data corruption, allowing them to make informed decisions with accurate, up-to-date information.
Key Characteristics
Row-level atomicity (minimum): A "record" is treated as an atomic unit. Updating a row happens all-at-once or not-at-all. You can't have half-updated rows where some fields changed but others didn't.
Transaction boundaries: Operations are grouped into transactions with clear begin and commit points. Multiple changes either all succeed together or all fail together.
Explicit concurrency control: When conflicts occur, they're detected and presented to users for resolution. Changes are never silently overwritten.
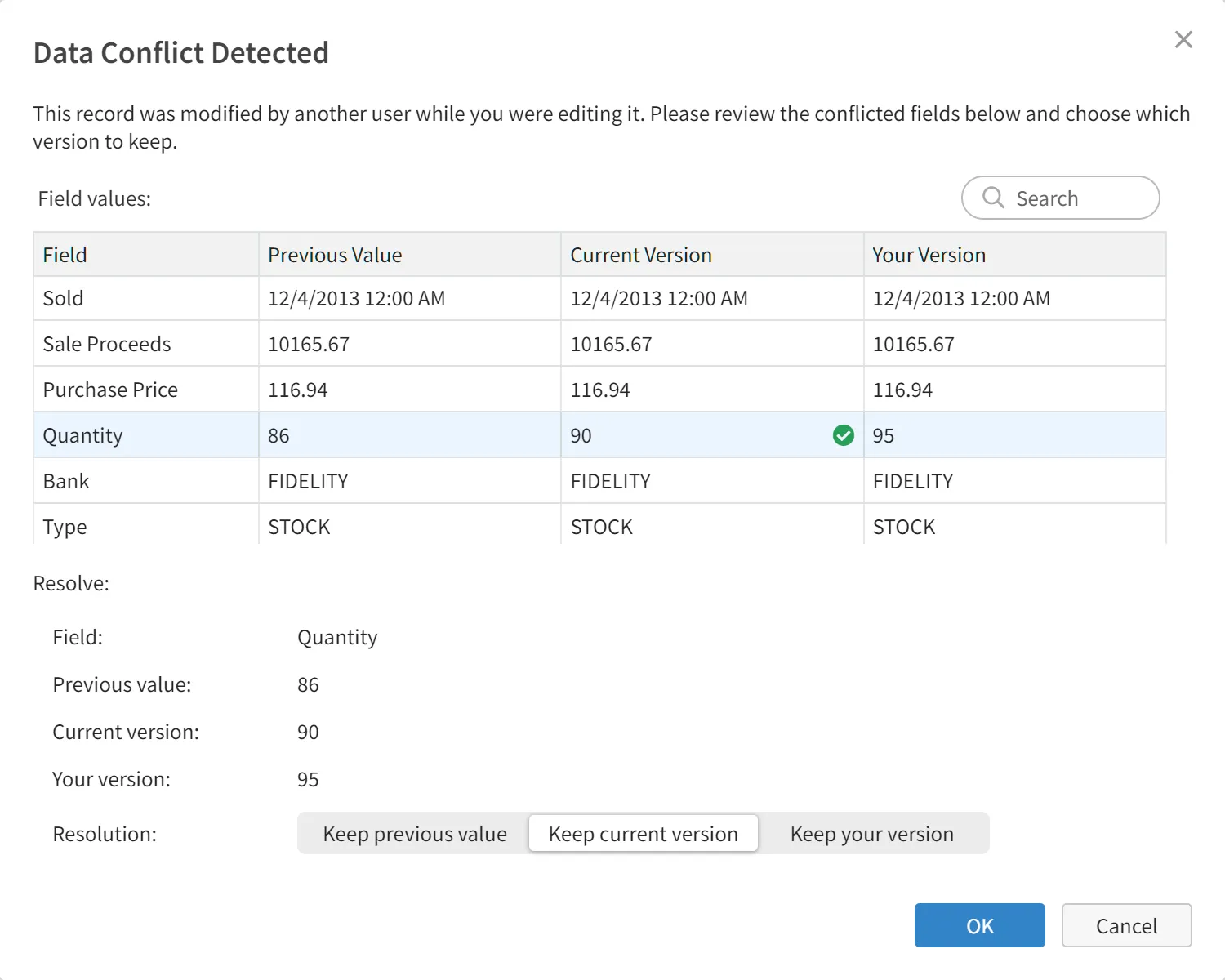
When conflicts occur, Visual DB offers a visual record merge interface that displays conflicting values side-by-side and allowing users to decide which versions to keep. This approach gives users control: they see exactly what changed, what they tried to change, and can make informed decisions about how to resolve conflicts, rather than facing a binary "accept theirs or accept mine" choice.
A Question for Software Developers
If you're a software developer, you'd never accept a version control system where developers constantly overwrite each other's code changes. Git, Mercurial, SVN—they all detect conflicts and force explicit resolution. So why accept a database tool that does exactly that with your data? Doesn't your business data deserve the same reliability standards as your source code?
The Bottom Line
Spreadsheet semantics optimize for collaboration speed. Database semantics optimize for data correctness.
When you're planning a company offsite, spreadsheet semantics are perfect. When you're managing patient prescriptions, financial transactions, or manufacturing tolerances, database semantics aren't optional—they're the only way to guarantee that the data in your system reflects reality.
The interface can look the same—a grid of rows and columns—but the guarantees underneath determine whether your system is suitable for mission-critical data or just lightweight collaboration.
Choose spreadsheet semantics when you want everyone typing together in real-time. Choose database semantics when data integrity is non-negotiable.
Understanding these fundamental differences helps you choose the right tool for your use case—and more importantly, helps you recognize that even tools using PostgreSQL underneath can fail to provide data integrity guarantees if they implement spreadsheet semantics.